


Essential Benchmarking for Trust & Safety
The newsletter for integrity engineering

📰 July 11th, 2023. Issue #16
You’re a platform that just hit some sort of scale and you’re strategizing ways to improve your Trust & Safety efforts. The utilization of rules engines and the influence of machine learning in the realm of Trust & Safety are relatively recent developments. These systems hold a crucial position in enabling prompt responses and effective content moderation. Whether obtained or developed in-house, these systems serve diverse purposes. However, when implementing them on your own platform, it is vital to oversee their performance to guarantee optimal adaptation. This entails considering platform policies, compliance, and linguistic context.
I outline a general process from systematic engineering principles and introduce Apollo, an open-source tool that implements four types of grading systems: programmatic, semantic, LLM-based, and human-based.
This newsletter will cover:
Types of monitoring
How and what to monitor
Importance of monitoring models/ranking systems
Defining key performance indicators
To ensure the success of your platform, it is crucial to foresee possible challenges that may emerge once you have implemented your automated tooling. In order to minimize these risks, it is important to focus your monitoring objectives on the following critical elements:
Preserving Model Performance: Safeguard your model against degradation by upholding its accuracy and effectiveness.
Detecting and Troubleshooting Errors: Promptly identify errors and notify your team for efficient troubleshooting. This facilitates data updates and model retraining to improve performance.
Maximizing Resource Utilization: Optimize resource allocation based on your team's system requirements and budgetary constraints.
Maintaining Pipeline Integrity: Ensure the functionality and efficiency of the established pipelines.
Assessing Business Implications: Evaluate the business value and impact of your model's predictions, measuring its contribution to the overall project success.
Metrics & Monitoring
In order to select appropriate metrics, it is crucial to establish a monitoring framework that aligns with the specific requirements of the platform and establishing linguistic context. This framework should enable the identification of the most relevant metrics to track, considering the desired levels of measurement.
For different types of tasks, such as classification and regression, various factors should be taken into account when choosing appropriate metrics. While metrics like accuracy, precision, F1-score, mean squared error (MSE), etc., are commonly used for classification and regression tasks, selecting metrics for generative foundation models presents its own set of challenges, which include:
Various Input Prompt Variations: When working with models or automated content moderation systems, determining the most effective input prompts, in this case platform UGC - can be difficult. Different prompts can lead to diverse outputs, emphasizing the importance of evaluating a range of inputs.
Uncertain Output Format: The output format of the model might lack clarity or straightforwardness. It could contain ambiguities or require additional interpretation, making it challenging to assess the quality and appropriateness of the generated output.
Multiple Output Metrics: Evaluating the output may involve considering multiple dimensions, such as confidence level, toxicity, bias, and more. It is crucial to carefully assess and prioritize the most relevant metrics for the specific application and domain.
Here is a compilation of essential inquiries to effectively monitor various aspects of your vendors or internal systems:
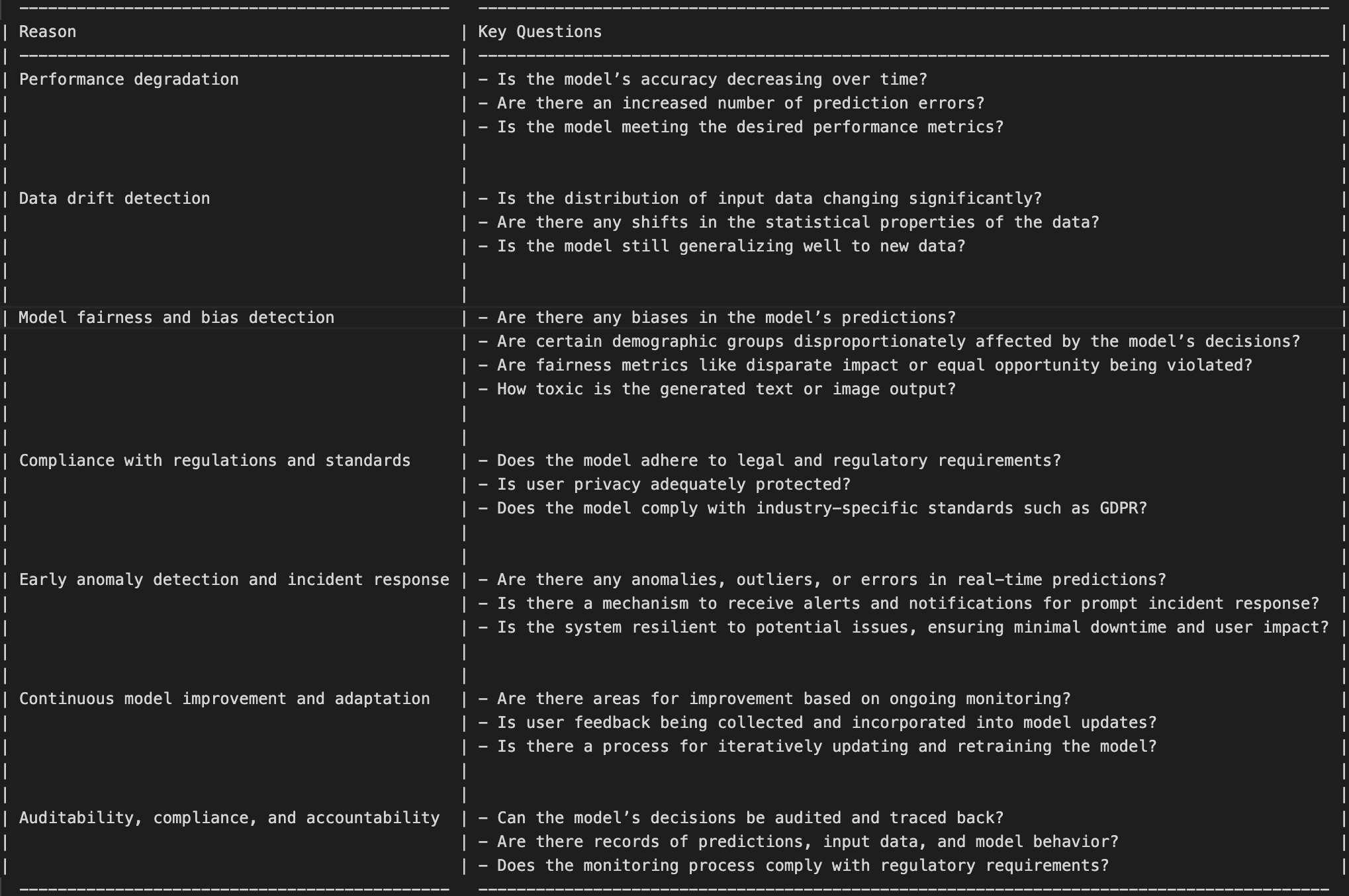
Model Performance Monitoring
If you want to monitor model quality either for vendors or internal systems, here is a comprehensive guide.
Expressing instructions in natural language (prompt engineering) provides inherent flexibility but also poses challenges. This flexibility stems from the fact that natural language instructions are user-defined and can differ between individuals and cultures. On the other hand, programming languages provide greater precision and accuracy in their instructions.
Apollo simplifies this process for benchmarking/testing Trust & Safety vendors and internal systems, allowing you to effortlessly manage it. Alternatively, you can leverage MLOps platforms tailored to your specific use case. These platforms facilitate seamless collaboration and provide alert feedback loops for quick troubleshooting of any issues that arise, such as model or data drifts.
Evaluation
By employing prompt engineering, you can assess your input data and its outcomes by supplying your model with diverse and varied examples. This approach enables you to test the model's capacity to generalize effectively based on the provided examples.
Gather User Feedback: Obtain feedback from moderators who engage with the prompts/UGC and ranking systems to make data driven decisions. Conduct surveys or interviews to gain insights into their satisfaction levels and evaluate quality of output.
Perform Comparisons: Assess the impact of various pieces of UGC by comparing their influence on the quality of the output.
Optimization
Conduct Prompt Modifications: Explore adjustments to prompts by incorporating additional context, or introducing constraints to influence the output.
Perform A/B Testing: Generate diverse variations of the prompt's output and solicit the LLM's input to select the optimal option (self-consistency). Compare the quality of the output, user satisfaction, or other pertinent metrics to identify the most effective prompt variations.
Iteratively Improve: Utilizing insights derived from evaluations, user feedback, and experiments, continuously refine prompt context. Integrate successful modifications into updated versions, while discarding or further optimizing less effective alternatives.
Model Monitoring
In recognition that accuracy alone does not encompass all aspects, Stanford researchers devised the Holistic Evaluation of Language Models (HELM) as a comprehensive benchmarking framework for LLMs.
HELM encompasses a range of multi-metric measurements that extend beyond isolated metrics such as accuracy. These include:
Accuracy: The model's capacity to make correct predictions in comparison to the ground truth labels.
Calibration: The alignment between the model's predicted probabilities and the true probabilities of its predictions. It reflects the confidence level or reliability of the model's probability estimates.
Robustness: The model's ability to maintain consistent performance even in the presence of variations or perturbations in the input data. Robust models demonstrate stability across different scenarios or data distributions.
Efficiency: The evaluation of the model's computational efficiency, including factors such as inference speed, memory usage, or energy consumption. Efficient models optimize resource utilization and can be deployed effectively in real-time or resource-constrained environments.
I'm building this
This blog post is just a really long way to say, I haven't found solutions to any of the above in the wild, so I'm building my own.
Check out Apollo, an open-source toolkit for integrity engineering that implements the process above and provides a way to extend model management with automation & data integrations.
Most notably, it includes a CLI that outputs a matrix view for quickly comparing outputs across multiple prompts, variables, and models. This means that you can easily compare prompts/scored pieces of UGC over hundreds or thousands of test cases and test vendor quality.